Tip of the day
Nope, no engine updates today. Instead I'll give you a website recommendation.
If you're a bit weird like me, that is, you rather read graphics papers than fiction before you go to sleep, you probably already have this one in your bookmarks.
Ke-Sen Huang keeps an index of all papers available online from every academic graphics conference worth it's name.
I'm yet to find a good rescource that lists all papers and presentations from more commercially oriented conferences like GDC. Feel free to share your own bookmarks :)
Friday, February 22, 2008
Wednesday, February 20, 2008
Soft shadows
Time for the screenshots:


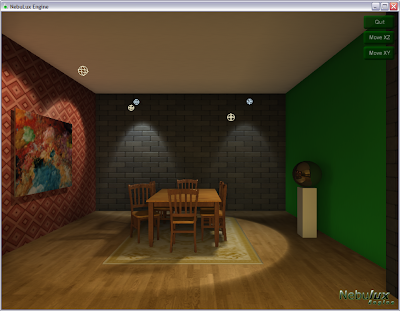 Soft shadows.
Soft shadows.
 The scene is also lit by an enviroment map.
The scene is also lit by an enviroment map.
I've added soft shadows to the engine. I use Percentage-Closer Soft Shadows (PCSS), described in this paper. It differs from regular PCF in that a "blocker-serach" step is used to approximate a shadow penumbra size. The estimated penumbra size is then used to control the filter size. It's not real penumbra shadows but it looks quite convincing.
Believe it or not, but until now my engine had no support for normal mapping. Now it does. The dynamic indirect lighting is also affected by the normal maps.Time for the screenshots:


Note the green light that is reflected from the wall (not visible) onto the scene.
 Soft shadows.
Soft shadows. The scene is also lit by an enviroment map.
The scene is also lit by an enviroment map.
Friday, February 08, 2008
Dynamic indirect lighting
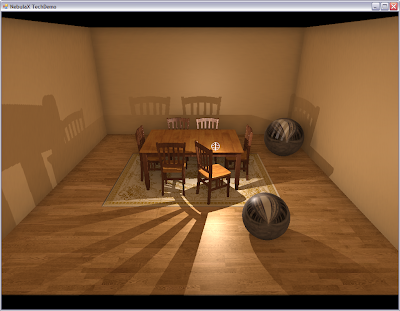
I got the indirect lighting to work correctly. There were some stupid bugs in my SH code. In the screenshots I use a 3x3x3 grid of sampling points (see last post) and one bonce of indirect light. There is also a (very) small constant ambient term so that no surfaces are completely black. Combined with SSAO it looks quite nice.
The scene is simple and HDR is deactivated so that the lighting effects is more apparent.



I got the indirect lighting to work correctly. There were some stupid bugs in my SH code. In the screenshots I use a 3x3x3 grid of sampling points (see last post) and one bonce of indirect light. There is also a (very) small constant ambient term so that no surfaces are completely black. Combined with SSAO it looks quite nice.
The scene is simple and HDR is deactivated so that the lighting effects is more apparent.



Friday, February 01, 2008
I've been quite busy with the engine lately. The new stuff is:
Dynamic reflections
Each reflective object has it's own cube enviroment map. I support multiple bounces by spreading out the cube map updates over a number of frames. This means there can be some subtle "popping" in the reflections. Acceptable for my application.
HDR pipeline
I now support 64 or 128 bit HDR rendering. Pretty standard stuff where I do tone mapping based on image luminance. Of course there is also a bloom filter (as if we're not tired of that one by now;))
Antialiasing
One of the biggest drawbacks with deferred shading is the lack of support for multisample antialias (at least with DX9). The usual thing to do is to hack antialias by performing an edge detection filter and blurring the image only on the edges. It's a dirty hack but it works quite well.
Dynamic indirect illumination
This is a variant of this paper. In short, I partition the world into a uniform grid, and at each grid point I capture the incident radiance field. This is done by rendering a cube map and then projecting it to spherical harmonics coefficients. The coefficients are stored in a number of volume textures. When rendering the frame, SH cofficients representing the incident radiance at each pixel are fetched from the volume texture and used to approximate the incident diffuse lighting at each pixel.
Right now there are some problems with my implementation but I'll solve that soon ;)
At last, the mandotary screenshot:

Dynamic reflections
Each reflective object has it's own cube enviroment map. I support multiple bounces by spreading out the cube map updates over a number of frames. This means there can be some subtle "popping" in the reflections. Acceptable for my application.
HDR pipeline
I now support 64 or 128 bit HDR rendering. Pretty standard stuff where I do tone mapping based on image luminance. Of course there is also a bloom filter (as if we're not tired of that one by now;))
Antialiasing
One of the biggest drawbacks with deferred shading is the lack of support for multisample antialias (at least with DX9). The usual thing to do is to hack antialias by performing an edge detection filter and blurring the image only on the edges. It's a dirty hack but it works quite well.
Dynamic indirect illumination
This is a variant of this paper. In short, I partition the world into a uniform grid, and at each grid point I capture the incident radiance field. This is done by rendering a cube map and then projecting it to spherical harmonics coefficients. The coefficients are stored in a number of volume textures. When rendering the frame, SH cofficients representing the incident radiance at each pixel are fetched from the volume texture and used to approximate the incident diffuse lighting at each pixel.
Right now there are some problems with my implementation but I'll solve that soon ;)
At last, the mandotary screenshot:

Thursday, January 10, 2008
I've finally started working on the engine after the holidays.
I've done quite a lot of non graphic stuff. I've improved the engine code here and there and I've added picking for example.
On the graphic side, I've added support for cube maps and thus omidirectional shadows. All lights now also supports gobos, i.e. color textures that are projected from the lights. There is also support for reflections, but I'm still working on dynamic ones.
Scenes with a lot of lights also means a lot of shadow maps. For this reason, I've implemented a shadow map queue. When a shadow map needs an update it's added to the queue and every frame a number of entries in the queue are removed and processed. So only a small number of shadow maps are updated each frame. This of course means that there can be some noticable shadow lag when objects are moved around. For the type of application I have in mind for this engine, that is acceptable.
 Omnidirectional shadow mapping
Omnidirectional shadow mapping
 Point- and spotlights with gobos
Point- and spotlights with gobos
 Lots of lights! All cast shadows and some use gobos.
Lots of lights! All cast shadows and some use gobos.
I've done quite a lot of non graphic stuff. I've improved the engine code here and there and I've added picking for example.
On the graphic side, I've added support for cube maps and thus omidirectional shadows. All lights now also supports gobos, i.e. color textures that are projected from the lights. There is also support for reflections, but I'm still working on dynamic ones.
Scenes with a lot of lights also means a lot of shadow maps. For this reason, I've implemented a shadow map queue. When a shadow map needs an update it's added to the queue and every frame a number of entries in the queue are removed and processed. So only a small number of shadow maps are updated each frame. This of course means that there can be some noticable shadow lag when objects are moved around. For the type of application I have in mind for this engine, that is acceptable.
 Omnidirectional shadow mapping
Omnidirectional shadow mapping Point- and spotlights with gobos
Point- and spotlights with gobos Lots of lights! All cast shadows and some use gobos.
Lots of lights! All cast shadows and some use gobos.Thursday, November 29, 2007
Light volumes and more
I've not been able to work much on the engine the last week since I've been busy with school projects.
Some things have been done though. I've updated the deferred rendering system to work with light volumes instead of full-screen quads. This alone provides a huge speedup as long as the lights are reasonably small. This also made me think about light attenuation. Funny enough, this thread at gamdev popped up today. As discussed in the thread, I also wanted to find a way to set a maximum radius for a light, without affecting its atenuation too much. After some playing around with Maple, I found that max(0, 1-1/maxRadius*x)/(1+k*x^2) does the job quite good (this function is suggested in the thread) . I implemented it in my lighting shaders and the result is fine. I also took the opportunity to shave of a few instructions.
Here are some screens:
I've not been able to work much on the engine the last week since I've been busy with school projects.
Some things have been done though. I've updated the deferred rendering system to work with light volumes instead of full-screen quads. This alone provides a huge speedup as long as the lights are reasonably small. This also made me think about light attenuation. Funny enough, this thread at gamdev popped up today. As discussed in the thread, I also wanted to find a way to set a maximum radius for a light, without affecting its atenuation too much. After some playing around with Maple, I found that max(0, 1-1/maxRadius*x)/(1+k*x^2) does the job quite good (this function is suggested in the thread) . I implemented it in my lighting shaders and the result is fine. I also took the opportunity to shave of a few instructions.
Here are some screens:


In the second shot there is 100+ lights. As you can see, the point lights does not cast shadows yet. I will also need to implement a 64 bit HDR pipeline as I get oversaturation and banding artifacts.
I've also ordered a AMD HD3870. While slightly slower than the Nvidia 8800GT, it's slightly cheaper and most importantly: it's available ;)
Tuesday, November 20, 2007
Eliminating noise
The last couple of days I have tried to reduse the noise in the SSAO output. It proved to be a hard problem. My initial attempt was to simply apply a separable gaussian blur. It produced a nice, smooth image. But as I expected it resulted in ugly halos around object edges when combined with the albedo term. Next I tried to combine the gaussian with some edge detection trickery. Looked kind of cool, but unfortunally it just reduced the halos and did not eliminate them.
Then I turned to bilateral upsampling (see Jeremy Shopf's blog). Eliminated halos, but the SSAO input was way to noisy for simple bilinear filtering. My last atempt was a combination of a box blur and a variant of bilateral filtering. The result is acceptable. I'm not satisfied, but it will do for now.
Next up is some speed optimizations and then I'm on to indirect lighting.

 SSAO + "bilateral filtering"-hack
SSAO + "bilateral filtering"-hack
The last couple of days I have tried to reduse the noise in the SSAO output. It proved to be a hard problem. My initial attempt was to simply apply a separable gaussian blur. It produced a nice, smooth image. But as I expected it resulted in ugly halos around object edges when combined with the albedo term. Next I tried to combine the gaussian with some edge detection trickery. Looked kind of cool, but unfortunally it just reduced the halos and did not eliminate them.
Then I turned to bilateral upsampling (see Jeremy Shopf's blog). Eliminated halos, but the SSAO input was way to noisy for simple bilinear filtering. My last atempt was a combination of a box blur and a variant of bilateral filtering. The result is acceptable. I'm not satisfied, but it will do for now.
Next up is some speed optimizations and then I'm on to indirect lighting.

 SSAO + "bilateral filtering"-hack
SSAO + "bilateral filtering"-hack
Subscribe to:
Posts (Atom)
